

Text Processing using GREP, SED, and AWK
Introduction to Text Processing in Linux
Text processing in Linux involves using various commands to manipulate and analyze text data efficiently. Commonly used commands include grep for searching through text, sed for stream editing, and awk for pattern scanning and processing. These commands allow users to perform tasks such as filtering, extracting, and transforming information from text files. The benefits of text processing include the automation of data handling, increased productivity, and greater precision in data analysis.
Text Processing Tools
Introduction to grep
The grep command in Unix/Linux is a powerful tool used for searching and manipulating text patterns within files. Its name is derived from the ed (editor) command g/re/p (globally search for a regular expression and print matching lines), which reflects its core functionality. grep is widely used by programmers, system administrators, and users alike for its efficiency and versatility in handling text data. In this article, we will explore the various aspects of the grep command.
grep searches the named input FILEs (or standard input if no files are named, or if a single hyphen-minus (-) is given as file name) for lines containing a match to the given PATTERN. By default, grep prints the matching lines.
How to install grep in Linux?
Grep comes pre-installed in almost every distribution of Linux. However, in case, we can install it with the below command in the terminal window if it is missing from our system:
$ sudo apt-get install grep
- The ‘grep’ command is generally used with pipe (|).
Syntax of grep Command in Unix/Linux grep [options] pattern [files]

or
command | grep <searchWord>

Options Available in grep Command
- -c: Prints only a count of the lines that match a
- -h: Displays the matched lines but does not display the
- -i: Ignores case for
- -l: Displays a list of filenames
- -n: Displays the matched lines along with their line
- -v: Prints all the lines that do not match the
- -e exp: Specifies an expression with this option; can be used multiple
- -f file: Takes patterns from a file, one pattern per
- -E: Treats the pattern as an extended regular expression (ERE).
- -w: Matches whole words
- -o: Prints only the matched parts of a matching line, each on a separate
- -A n: Prints the matched line and n lines after the
- -B n: Prints the matched line and n lines before the
- -C n: Prints the matched line and n lines before and after the
Let’s start with some basic grep operations:-
- Open a
- Use the following command to create the filetxt:

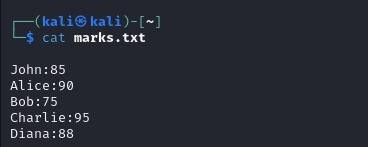
This creates a sample file with names and marks.
Verify the content of marks.txt:
Use grep with a pipe
Execute the command to filter data containing ‘9’

Use grep without a pipe
Run the grep command directly:

Advanced Grep Usage
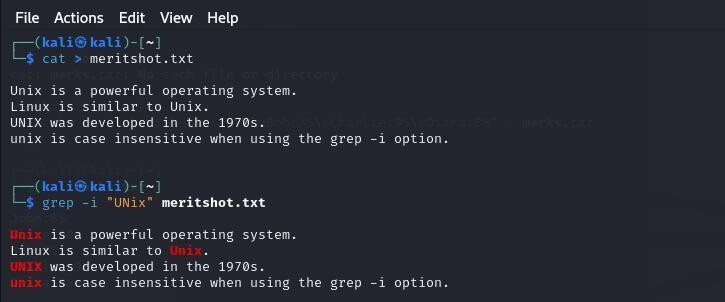
- Case insensitive search
The -i option enables to search for a string case insensitively in the given file. It matches the words like “UNIX”, “Unix”, “unix”.
2. Count the Number of Matches
Displaying the Count of Number of Matches Using grep
We can find the number of lines that matches the given string/pattern

3. Display the File Names that Matches the Pattern Using grep
We can just display the files that contains the given string/pattern.

4. Checking for the Whole Words in a File Using grep
By default, grep matches the given string/pattern even if it is found as a substring in a file. The -w option to grep makes it match only the whole words.

Some More Practical Examples of grep Command in Linux
Example-1:
To Search for the given string in a single file test.sh
$ cat test.sh #!/bin/bash fun()
echo “This is a test.”
# Terminate our shell script with success message exit 1
fun()
from above file grep exit:
$ grep “exit” demo_file
output:
exit 1
Example-2:
To Checking for the given string in multiple files: in this case test.sh and test1.sh
$ cat test.sh #!/bin/bash fun()
echo “This is a test.”
# Terminate our shell script with success message exit 1
fun()
$ cat test1.sh #!/bin/bash fun()
echo “This is a test1.”
# Terminate our shell script with success message exit 0
fun()
grep exit in both files test.sh and test1.sh:
$ grep exit test*
output:
test1.sh: exit 0
test.sh: exit 1
Example-3:
To Case insensitive search using grep -i, added EXIT in test1.sh
$ cat test1.sh #!/bin/bash fun()
echo “This is a test1.”
# Terminate our shell script with success message, EXIT with 0 exit 0
fun()
$ grep exit test1.sh test1.sh:
exit 0
$ grep -i exit test*
output:
test1.sh:
# Terminate our shell script with success message, EXIT with 0 test1.sh:
exit 0
two lines with -i option, as its case insensitive.
Example-4:
To Match regular expression in files
$ grep “This.*test” test1.sh
output:
echo “This is a test1.”
Introduction to Sed
- sed (Stream Editor) is a powerful tool for parsing and transforming
- It is commonly used for making automated edits to files or output
- sed can perform various tasks such as:
- Search and replace
- Delete or insert
- Edit text according to specific
- It works by reading input line by line, applying the specified operations, and outputting the results.
Options
- -n suppress automatic printing of pattern space
- -i edit files inplace (makes backup if SUFFIX supplied)
- -r use extended regular expressions
- -e add the script to the commands to be executed
- -f add the contents of script-file to the commands to be executed
Commands
Three commonly used commands
- d: Delete the pattern space (removes lines matching the pattern).
- p: Print out the pattern space (displays lines matching the pattern).
- s: Search and replace (substitute one string with another).
Let’s start with some basic sed operations:-
First, create a new file to work with:

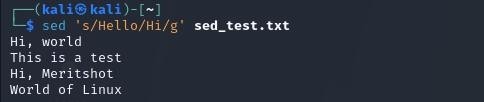
This replaces the first occurrence of “Hello” with “Hi” on each line. The s command in sed stands for “substitute”.
To replace all occurrences on each line, use the global flag:
This command modifies the file directly, replacing “world” with “sed”.
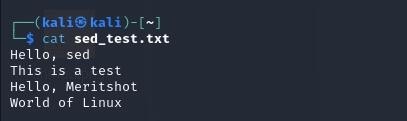
Let’s check the contents of the file to see the changes:
Explanation:
- sed: The command used to edit
- ‘s/Hello/Hi/’: A sed command that substitutes “Hello” with “Hi”.
- g flag: The g at the end of ‘s/Hello/Hi/g’ makes the substitution global, replacing all occurrences.
- -i option: Edits the file in-place, modifying the file instead of just outputting the changes.
Advanced Sed Usage
Now that we understand the basics of sed, let’s explore some more advanced features that make it a powerful tool for text manipulation.
1.Deleting lines:

This deletes the second line of the file. The d command in sed stands for “delete”.
2. Inserting text:
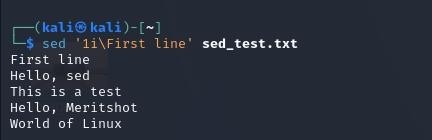
This inserts “First line” before the first line of the file. The i command stands for “insert”.
3. Appending text:
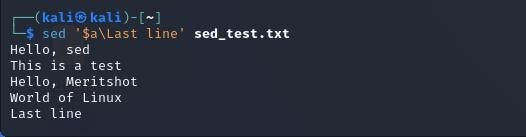
This appends “Last line” at the end of the file. The a command stands for “append”, and $ represents the last line.
4. Multiple commands:

This applies multiple substitutions in one command. The -e option allows you to specify multiple sed commands.
Explanation:
- 2d: Deletes the second You can change the number to delete different lines.
- 1i\: Inserts text before the first Change the number to insert at different positions.
- $a\: Appends text at the end of the
- -e: Allows you to specify multiple sed commands in a single
- [Ww]: A regular expression that matches either uppercase “W” or lowercase “w”.
Important note:
- These changes are not saved to the file unless you use the -i
Introduction to Awk
- Pattern Scanning and Text Processing Language: awk is a powerful tool for handling structured data and performing pattern scanning and text
- Origin of Name: awk is named after its creators — Alfred Aho, Peter Weinberger, and Brian Kernighan.
- Text Processing: awk processes each line of input as a record and each word on the line as a field.
What Can We Do with Awk?
AWK Operations:
- Scans a file line by
- Splits each input line into
- Compares input lines or fields to specified
- Performs actions on matched
Useful For:
- Transforming data
- Producing formatted
Programming Constructs:
- Formatting output
- Performing arithmetic and string
- Using conditionals and
Key Features of Awk:
- Scripting Language: Allows users to write short programs without the need for compiling.
- Variable Support: Supports variables, numeric functions, string functions, and logical operators.
- Process text files: Analyzing and manipulating data in text
- Pattern scanning and processing: Searching for patterns within files and performing specified actions when those patterns are found.
- Data extraction and reporting: Generating formatted reports from a text database or any structured data.
- Text transformation and manipulation: Efficiently handling and transforming data or text within files.
Syntax of grep Command in Unix/Linux

Options:
- -f program-file : Reads the AWK program source from the file program-file, instead of from the first command line argument.
- -F fs : Use fs for the input field separator
Let’s start with some basic awk operations:
First, create a new file with some structured data:

This creates a file named awk_test.txt with a header row and four data rows.
Now, let’s use awk to print specific fields:

This prints the first and second fields of each line.
We can also use conditions:

This prints names of people over 28 years old.
calculates and prints the average age:

This calculates and prints the average age, skipping the header row.
Explanation:
- In awk, each line is automatically split into fields, typically by
- $1, $2, , refer to the first, second, etc., fields in each line.
- NR is a built-in variable that represents the current record (line)
- The END block is executed after all lines have been
- sum += $2 adds the value of the second field (age) to a running
Summary
Three powerful text processing commands in Linux:
1.Grep-Pattern Searching:
- Purpose: grep (Global Regular Expression Print) is a command-line utility used to search for patterns within files or input streams.
Features:
- Supports regular expressions for complex
- Can search in multiple files and display matching
- Options include case-insensitive search (-i), counting matches (-c), showing filenames (-l), and inverting matches (-v).
Example Uses:
- Searching logs or large text files for specific
- Finding specific patterns, like IP addresses, email addresses, or keywords
2. sed – Stream Editor:
- Purpose: sed (Stream Editor) is used for stream editing—modifying text from input files or streams.
Features:
- It can replace, insert, delete, and transform text within
- Supports regular expressions for powerful text
- Changes made using sed can be done in-place (directly modifying the file).
- Useful for automating edits in configuration files or log
Example Uses:
- Replacing text in files (sed ‘s/old/new/’ filename).
- Removing unwanted characters or lines from
- Editing files in place with -i (e.g., sed -i ‘s/old/new/g’ file).
- Extracting or modifying parts of files based on
3. awk – Text Processing and Data Extraction:
- Purpose: awk is a text processing language used for data extraction and reporting. It’s particularly useful for processing tabular or structured data, such as CSV, TSV, or log files.
Features:
- Supports text processing, arithmetic operations, and conditional logic.
- Useful for extracting specific columns or summarizing
Example Uses:
- Extracting specific columns from a CSV
- Summarizing data, like counting occurrences of specific entries in a
- Performing calculations (e.g., summing values from a column of numbers).
- Formatting output (like adding headers to tables).
These tools are essential for Linux users and admins, streamlining file searches, text modifications, and data extraction. With practice, they simplify many text processing tasks in daily Linux work.












