
1. Adversarial Machine Learning
Adversarial machine learning is a machine learning method that aims to trick machine learning models by providing deceptive input. Hence, it includes both the generation and detection of adversarial examples, which are inputs specially created to deceive classifiers. Such attacks, called adversarial machine learning, have been extensively explored in some areas, such as image classification.
2. The Threat of Adversarial Attacks in Machine Learning
With machine learning rapidly becoming core to organizations’ value proposi- tion, the need for organizations to protect them is growing fast. Hence, Adver- sarial Machine Learning is becoming an important field in the software industry. Google, Microsoft, and IBM have started to invest in securing machine learning systems. In recent years, companies are heavily investing in machine learning themselves – Google, Amazon, Microsoft, and Tesla – faced some degree of adversarial attacks. Moreover, governments start to implement security stan- dards for machine learning systems, with the European Union even releasing a complete checklist to assess the trustworthiness of machine learning systems (Assessment List for Trustworthy Artificial Intelligence – ALTAI).
Gartner, a leading industry market research firm, advised that “application leaders must anticipate and prepare to mitigate potential risks of data corrup- tion, model theft, and adversarial samples”.
Recent studies show that the security of today’s AI systems is of high im- portance to businesses. However, the emphasis is still on traditional security. Organizations seem to lack the tactical knowledge to secure machine learning systems in production. The adoption of a production-grade AI system drives the need for Privacy-Preserving Machine Learning (PPML).

3. Why Are They a Threat?
Adversarial attacks highlight a critical vulnerability in machine learning models: their inability to generalize well beyond their training data. This vulnerability is not just a theoretical concern but has been demonstrated in numerous practical scenarios, necessitating robust defenses. For example:
- In cybersecurity, adversarial attacks can trick malware detectors, allowing malicious software to bypass
- In facial recognition systems, subtle alterations to an image can cause misidentification, leading to security
- Deception of Models: Adversarial attacks introduce subtle, often im- perceptible changes to input data, causing models to make incorrect pre- dictions or classifications. This can lead to serious errors, especially in critical applications like autonomous driving, healthcare, and
- Security Risks: In applications such as cybersecurity, adversarial attacks can trick models into misclassifying malicious inputs as benign, allowing attackers to bypass security measures and potentially cause
- Privacy Breaches: Certain types of adversarial attacks, like model in- version attacks, can extract sensitive information about the training data, leading to potential privacy violations and data
Compromised Decision Making: In decision-critical systems, adver- sarial attacks can lead to faulty decisions, such as incorrect medical diag- noses, financial fraud detection failures, or erroneous autonomous vehicle navigation, with potentially catastrophic outcomes.
4. Understanding Machine Learning Robustness: Why It Matters and How It Affects Your Mod- els
4.1 What is Machine Learning Robustness?
Machine learning robustness refers to the ability of a model to maintain its per- formance when faced with uncertainties or adversarial conditions. This includes handling noisy data, distribution shifts, and adversarial attacks, among other challenges. A robust model should be able to generalize well and provide reliable predictions even when dealing with unforeseen inputs or circumstances.
4.2 The Importance of Robustness in Machine Learning
The real-world consequences of non-robust models can be severe, ranging from financial losses to compromised safety. For instance, an autonomous vehicle that relies on a non-robust image recognition system could misinterpret road signs or fail to detect obstacles, leading to accidents. Similarly, a non-robust fraud detection system might result in false positives or negatives, causing significant financial losses for businesses and consumers. As machine learning becomes increasingly embedded in our daily lives, the importance of robust models grows. In addition to ensuring accurate predictions, robust models can contribute to enhanced security, privacy, and user trust in AI systems.
4.3 Robustness vs. Accuracy Trade-off
In many cases, there is a trade-off between model robustness and accuracy. While it may be tempting to focus on achieving the highest possible accuracy on a given dataset, doing so might result in overfitting or a lack of generalization to new data. Overfitting occurs when a model is trained too well on the training data, capturing noise and random fluctuations rather than learning the under- lying patterns. Consequently, the model performs poorly when exposed to new, unseen data. On the other hand, underfitting occurs when a model is too simple to capture the complexity of the data, resulting in suboptimal performance on both the training and test datasets. Striking the right balance between robust- ness and accuracy is critical for developing effective machine-learning models.

However, Robustness vs. Accuracy Trade-off is a bit different. We should increase our model’s generalization further, ensuring its stability even when faced with shifted or modified datasets.
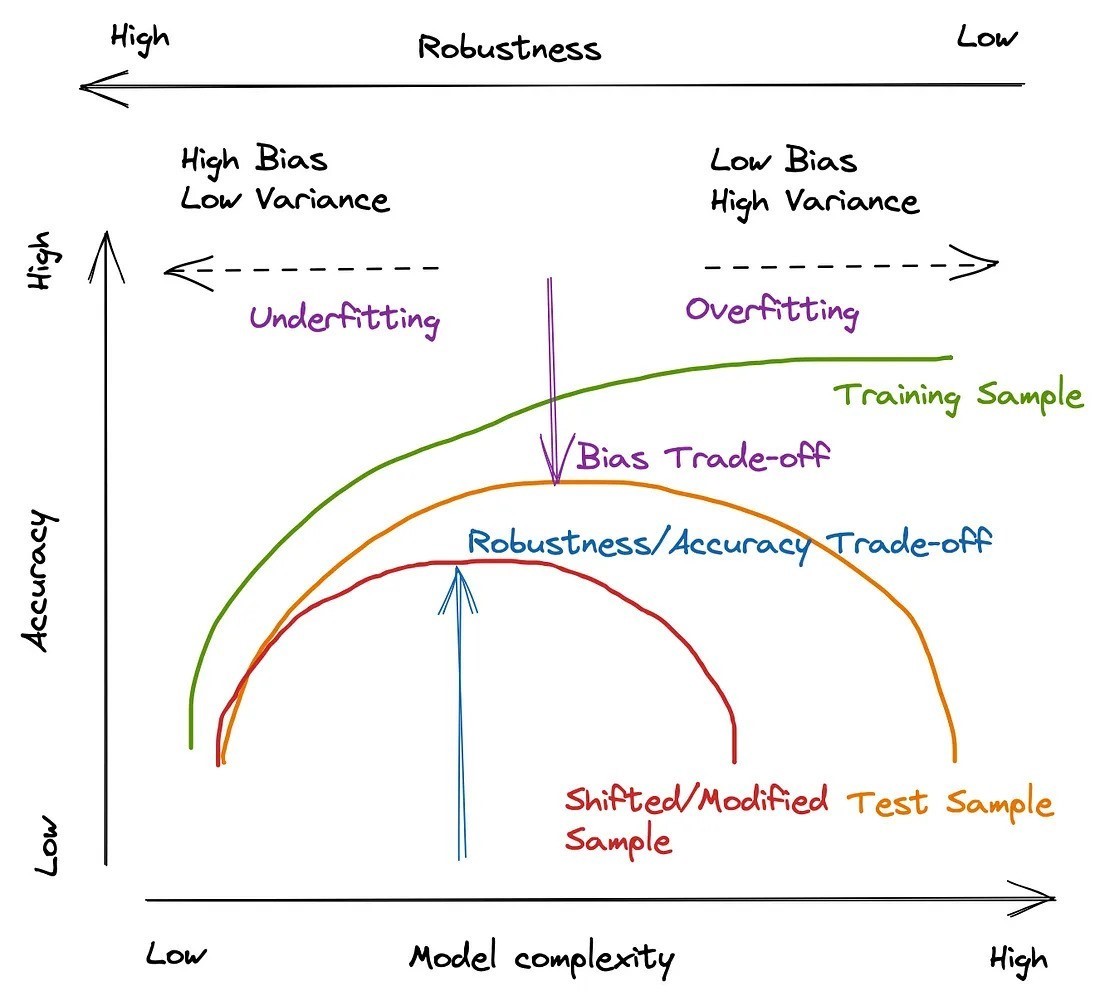
4.4 Challenges in Achieving Robustness
There are several challenges to achieving robustness in machine learning models, some of which include:
- Noisy data: Real-world data is often noisy, containing errors, inconsisten- cies, and missing values. Developing models that can handle such data without sacrificing performance is crucial for ensuring
- Distribution shifts: The data used to train a model may not always be representative of the data it encounters in real-world applications. Models need to be robust to such distribution shifts to maintain their
- Adversarial attacks: As machine learning models become more prevalent, they become targets for adversarial attacks designed to manipulate their outputs or expose vulnerabilities. Robust models should be resilient to such
- Model complexity: Striking the right balance between model complexity and robustness can be challenging. Overly complex models may be more prone to overfitting and less interpretable, while simpler models may strug- gle to capture the intricacies of the data.
4.5 Strategies for Enhancing Robustness
Throughout this blog series, we will delve into various strategies for enhancing the robustness of machine learning models, including:
- Data augmentation and preprocessing: By augmenting and preprocessing the data, we can improve the model’s ability to handle noisy inputs and generalize to new data. Techniques such as data cleaning, normalization, and various augmentation methods can help create a more diverse and robust dataset for
- Regularization techniques: Regularization methods, such as L1 and L2 regularization, dropout, and early stopping, can help prevent overfitting and improve model robustness. These techniques add constraints to the model training process to encourage simpler models that generalize
- Ensemble learning and model diversity: Combining multiple models with different strengths and weaknesses can lead to a more robust overall sys- Ensemble learning techniques, such as bagging, boosting, and stack- ing, leverage the power of diverse models to create a stronger, more robust predictor.
- Transfer learning and domain adaptation: Transfer learning allows a model trained on one task to be fine-tuned for a related task, often with fewer training examples. Domain adaptation techniques enable models to adapt to distribution shifts, making them more robust to changes in the data
- Interpretability and explainability: Developing models that are interpretable and explainable can help identify potential weaknesses and vulnerabilities, enabling us to build more robust Techniques for understanding and explaining model decisions can also contribute to increased user trust in AI systems.
- Robustness metrics and evaluation: To ensure that our models are truly robust, we need to measure their performance using appropriate evalu- ation metrics. Traditional performance metrics may not always capture the nuances of robustness, so we must also consider robustness-specific evaluation techniques and benchmark
5 How Adversarial Attacks on AI Systems Work
There are a large variety of different adversarial attacks that can be used against machine learning systems. Many of these work on deep learning systems and traditional machine learning models such as Support Vector Machines (SVMs) and linear regression. Most adversarial attacks usually aim to deteriorate the performance of classifiers on specific tasks, essentially to “fool” the machine learning algorithm. Adversarial machine learning is the field that studies a class of attacks that aims to deteriorate the performance of classifiers on specific tasks. Adversarial attacks can be mainly classified into the following categories:
- Poisoning Attacks
- Evasion Attacks
- Model Extraction Attacks
5.1 Poisoning Attacks
The attacker influences the training data or its labels to cause the model to underperform during deployment. Hence, Poisoning is essentially adversarial contamination of training data. As ML systems can be re-trained using data col- lected during operation, an attacker may poison the data by injecting malicious samples during operation, which subsequently disrupt or influence re-training.
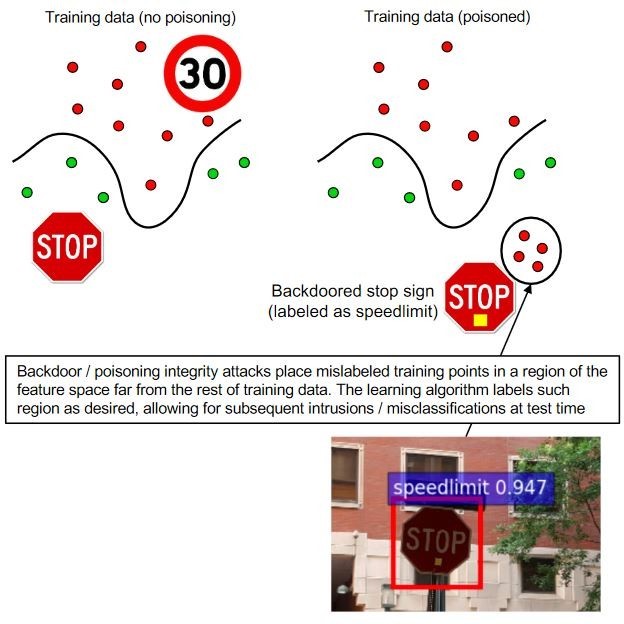
5.2 Evasion Attacks
Evasion attacks are the most prevalent and most researched types of attacks. The attacker manipulates the data during deployment to deceive previously trained classifiers. Since they are performed during the deployment phase, they are the most practical types of attacks and the most used attacks on intrusion and malware scenarios. The attackers often attempt to evade detection by obfuscating the content of malware or spam emails. Therefore, samples are modified to evade detection as they are classified as legitimate without directly impacting the training data. Examples of evasion are spoofing attacks against biometric verification systems.
5.3 Model Extraction
Model stealing or model extraction involves an attacker probing a black box machine learning system in order to either reconstruct the model or extract the data it was trained on. This is especially significant when either the training data or the model itself is sensitive and confidential. Model extraction attacks can be used, for instance, to steal a stock market prediction model, which the adversary could use for their own financial benefit.
6 How to Achieve Model Robustness?
Making machine learning models robust involves several techniques to ensure strong performance on unseen data for diverse use cases. The following section discusses the factors that contribute significantly to achieving model robustness.
6.1 Data Quality
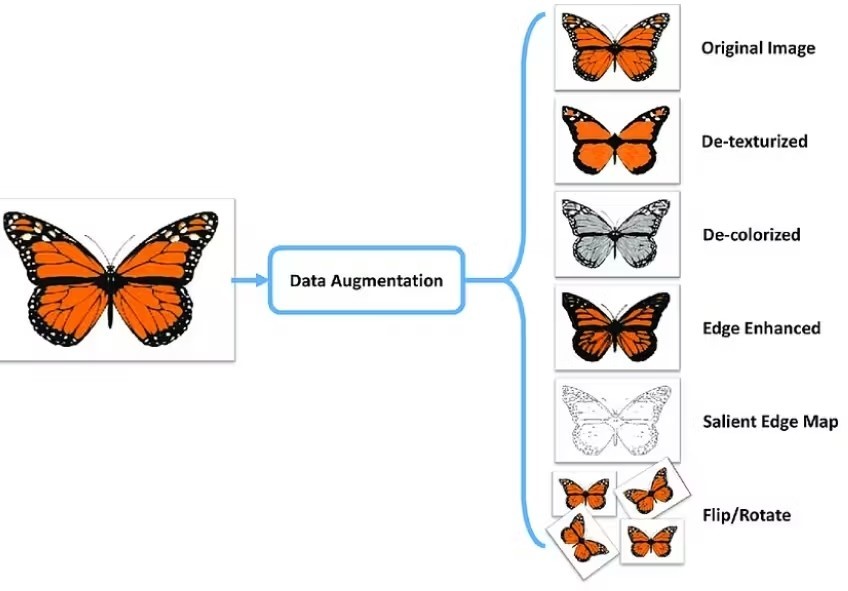
High data quality enables efficient model training by ensuring the data is clean, diverse, consistent, and accurate. As such, models can quickly learn underly- ing data patterns and perform well on unseen samples without exhibiting bias, leading to higher robustness. Automated data pipelines are necessary to im- prove data quality as they help with data preprocessing to bring raw data into a usable format. The pipelines can include statistical checks to assess diversity and ensure the training data’s representativeness of the real-world population. Moreover, data augmentation, which artificially increases the training set by modifying input samples in a particular way, can also help reduce model over- fitting. The illustration below shows how augmentation works in CV.
Lastly, the pipeline must include a vigorous data annotation process, as model performance relies heavily on label quality. Labeling errors can cause the model to generate incorrect predictions and become vulnerable to adversarial attacks.
A clear annotation strategy with detailed guidelines and a thorough review process by domain experts can help improve the labeling workflow. Using active learning and consensus-based approaches such as majority voting can also boost quality by ensuring consistent labels across samples.
7 Examples and Case Studies of Robust Ma- chine Learning Against Adversarial Attacks
Cybersecurity: Microsoft Defender ATP
Example: Microsoft’s Robust Machine Learning for Malware Detec- tion
Microsoft Defender Advanced Threat Protection (ATP) uses machine learning to detect malware. Adversarial attacks against such systems involve modifying malware to evade detection. Microsoft has incorporated adversarial training, where malware detectors are trained with adversarial examples, significantly enhancing the robustness of their detection models against sophisticated eva- sion techniques.
Autonomous Vehicles: Tesla Autopilot
Case Study: Tesla’s Defense Against Adversarial Attacks on Au- tonomous Driving
Tesla has faced challenges with adversarial attacks on their autonomous vehicle systems. These attacks could involve altering road signs or lane markings to confuse the vehicle’s perception system. Tesla has utilized adversarial training to make its models more robust, training them on both normal and adversar- ial examples to ensure that their perception algorithms can handle adversarial inputs effectively.
Healthcare: Robust Medical Image Analysis
Example: Robust Image Recognition in Medical Imaging
Adversarial attacks in healthcare, particularly on medical imaging systems, can alter diagnostic outcomes. For example, small perturbations to MRI or CT scan images could mislead diagnostic algorithms. Researchers have developed robust convolutional neural networks (CNNs) that are trained with adversarial examples, making these models more resistant to manipulations and ensuring accurate diagnostic outcomes.
Financial Services: Fraud Detection Systems
Case Study: Fraud Detection at PayPal
Financial institutions like PayPal employ machine learning models for fraud detection. Adversarial attacks can mimic legitimate transactions to avoid de- tection. PayPal has implemented ensemble learning and adversarial training to improve the robustness of its fraud detection models. This involves train- ing multiple models and combining their predictions to mitigate the impact of adversarial transactions.
Facial Recognition: Facebook
Example: Robust Face Recognition Systems
Facebook uses robust machine learning techniques to enhance the security of its facial recognition systems. These systems are vulnerable to adversarial attacks that slightly alter facial images to evade detection. By employing adversarial training and techniques like feature squeezing, Facebook has improved the ro- bustness of its facial recognition algorithms, ensuring reliable identification and authentication even under adversarial conditions.
Natural Language Processing (NLP): Google’s BERT
Case Study: Google’s BERT and Adversarial Training
Google’s BERT model has been enhanced to defend against adversarial attacks in NLP. These attacks often involve subtle changes to text that alter its mean- ing and mislead the model. Google has incorporated adversarial training and defensive distillation techniques, where the model is trained on adversarial ex- amples to improve its robustness against such manipulations, thereby enhancing its performance on tasks like sentiment analysis and question answering.
Speech Recognition: Amazon Alexa
Example: Robust Speech Recognition by Amazon Alexa
Amazon has improved the robustness of Alexa’s speech recognition systems against adversarial attacks. Attackers can create audio adversarial examples that sound normal to humans but cause recognition errors. By using adver- sarial training and noise augmentation, Amazon has made Alexa’s models more resistant to these attacks, ensuring accurate speech recognition even in the pres- ence of adversarial noise.
Challenges and Limitations of Machine Learning
Challenges of Machine Learning
Data Quality and Quantity
Challenge: Machine learning algorithms are voracious consumers of data, but they demand high-quality data. Garbage in, garbage out — the adage rings true in the world of ML. The data used for training machine learning models should be clean, accurate, and representative of the problem. Data preprocessing, cleaning, and augmentation are often required to ensure data quality. Additionally, having a sufficient quantity of data is crucial, as models need diverse examples to learn effectively.
Real-life Example: Healthcare providers rely on patient records to train diagnostic models. Incomplete or inaccurate data can lead to erroneous predic- tions, risking patient health.
Overfitting and Underfitting
Challenge: Machine learning models can overfit (become overly complex) or underfit (too simplistic). Striking the right balance is critical for model per- formance. Overfitting occurs when a model fits the training data too closely, capturing noise instead of useful patterns. Underfitting results from overly sim- plistic models that can’t capture complex relationships in the data. Addressing these issues often involves hyperparameter tuning and cross-validation.
Real-life Example: In stock market prediction, an overfit model may per- form exceptionally well on historical data but fail to generalize to new market conditions, leading to poor investment decisions.
Interpretability and Explainability
Challenge: Many machine learning models operate as “black boxes,” mak- ing it challenging to comprehend the reasoning behind their decisions. Inter- pretability and explainability are crucial in applications where human lives or significant financial decisions are at stake. Understanding why a model made a specific decision can be essential for transparency, accountability, and trust.
Real-life Example: In the context of autonomous vehicles, understanding why a self-driving car made a specific decision is vital for safety and account- ability.
Generalization
Challenge: A successful machine learning model should perform well on new, unseen data. Achieving this generalization is often tricky. Ensuring that a model generalizes effectively is a core challenge. Overfit models may perform well on training data but fail to make accurate predictions on new, unseen data. Techniques such as cross-validation and regularization are employed to improve generalization.
Real-life Example: A spam email classifier may excel in identifying com- mon spam, but it could falter when new, sophisticated spam techniques emerge.
Bias and Fairness
Challenge: Machine learning models can inadvertently inherit biases present in their training data, leading to unfair or discriminatory outcomes. Biases in training data can result from historical prejudices, unequal representation, or data collection methods. Addressing bias and ensuring fairness in models is cru- cial, particularly in applications like hiring and lending, where discrimination can have serious consequences.
Real-life Example: Hiring algorithms can unintentionally favor candidates from specific demographic groups, contributing to discrimination in the recruit- ment process.
Computational Resources
Challenge: Training deep learning models, especially large neural net- works, requires substantial computational resources, including powerful GPUs and TPUs. Deep learning models with millions of parameters demand signifi- cant computing power. This not only drives up costs but also raises concerns about energy consumption and environmental impact.
Real-life Example: Training state-of-the-art language models like GPT-3 demands massive computing power and energy consumption, raising environ- mental concerns.
Model Selection
Challenge: Selecting the appropriate machine learning algorithm or model architecture for a specific problem can be perplexing. Choosing the wrong one may result in suboptimal performance. The choice of model depends on the data type, problem type (classification, regression, clustering), and the desired out- put. It also involves deciding between traditional machine learning algorithms and deep learning methods.
Real-life Example: Image recognition tasks benefit from convolutional neural networks (CNNs), while natural language processing tasks require recur- rent neural networks (RNNs).
7.1 Limitations of Machine Learning
No Common-Sense Understanding
Limitation: Machine learning models lack common-sense understanding, which means they can make predictions based solely on statistical patterns without genuine comprehension. While machine learning models can identify correlations and patterns in data, they don’t possess true understanding or consciousness. This limitation makes them susceptible to making predictions based on spurious correlations.
Real-life Example: A language model may generate coherent sentences, but it doesn’t truly understand the context or meaning of the words it uses.
Data Dependency
Limitation: Machine learning models are highly dependent on the data they are trained on. They can’t provide meaningful insights beyond their train- ing data. Machine learning models make predictions based on the patterns
they’ve learned from historical data. They can’t offer insights or predictions about events or phenomena that fall outside the scope of their training data.
Real-life Example: A sentiment analysis model trained on restaurant re- views can’t offer insights into political sentiment.
Data Privacy and Security
Limitation: Machine learning often involves processing sensitive data, rais- ing concerns about privacy and security breaches. Machine learning applica- tions, especially in healthcare, finance, and personalization, often require access to sensitive data. Safeguarding this data from breaches and ensuring compliance with data protection regulations are significant challenges.
Real-life Example: Healthcare providers must ensure that patient data is securely processed and stored when using machine learning for diagnostics.
Model Robustness
Limitation: Machine learning models can be fragile. Small changes in input data can result in incorrect predictions or cause the model to fail. Models can be sensitive to minor changes in input data, which is problematic when deployed in real-world environments where data may be noisy or incomplete. Ensuring model robustness is a continuous challenge.
Real-life Example: In an image recognition system, minor alterations to an image may render it unrecognizable to the model.
Scalability
Limitation: Scaling machine learning solutions to handle increased data volumes and user traffic can be challenging, requiring substantial infrastruc- ture investments. As organizations grow and the volume of data and users increases, machine learning systems may need to be re-architected to maintain performance. This involves investing in infrastructure, distributed computing.
Real-life Example: E-commerce websites must invest in powerful servers and databases to scale up recommendation systems as their customer base grows.
Conclusion: Adversarial Machine Learning Mod- els
Adversarial machine learning models have emerged as crucial tools in enhancing the robustness and security of AI systems against adversarial attacks. These models play a pivotal role in various applications by implementing advanced techniques to detect, mitigate, and adapt to adversarial threats.
Applications and Advancements
Enhanced Security in Image Recognition: Adversarial machine learning models have significantly bolstered security in image recognition systems by im- plementing robust training techniques such as adversarial training and defensive distillation. These methods enable models to resist perturbations designed to
deceive them, ensuring reliable performance in critical applications like medical diagnostics and autonomous driving.
Secure Natural Language Processing (NLP) Systems: In NLP, adversar- ial machine learning models are employed to defend against text-based attacks, including adversarial examples crafted to manipulate sentiment analysis or spam detection algorithms. Techniques like adversarial training with diverse adver- sarial examples and incorporating robustness metrics enhance the resilience of NLP systems to malicious inputs.
Protecting Financial Systems: Adversarial machine learning models are utilized in financial systems to detect and prevent fraud attempts. By continu- ously learning from adversarial attempts to deceive fraud detection algorithms, these models improve their ability to distinguish between genuine and fraudulent transactions, safeguarding financial institutions and their customers.
Defense in Autonomous Vehicles: Autonomous vehicles rely on adversarial machine learning models to enhance their decision-making processes. These models detect and mitigate adversarial inputs that could compromise vehicle safety, ensuring reliable performance in diverse environmental conditions and unforeseen scenarios.
Future Directions
The field of adversarial machine learning continues to evolve, presenting new opportunities and challenges for research and development:
Advanced Adversarial Training Techniques: Future research aims to de- velop more sophisticated adversarial training techniques that can effectively defend against evolving adversarial attacks across different modalities and ap- plications.
Interdisciplinary Collaboration: Collaboration between machine learning experts, cybersecurity specialists, and domain-specific professionals is essential to develop holistic approaches to adversarial machine learning.
Real-world Deployment Challenges: Overcoming challenges related to com- putational resources, scalability, and integration into existing systems will be crucial for widespread adoption of adversarial machine learning models.
In conclusion, adversarial machine learning models represent a significant advancement in defending AI systems against adversarial attacks across various domains. By leveraging advanced techniques and continuous innovation, these models pave the way for more secure, reliable, and resilient AI applications in the future.

