

Introduction
Reinforcement learning is a type of machine learning where a computer program, called an agent, learns to make decisions by interacting with an environment and receiving rewards or penalties for its actions. The goal is to maximise the cumulative reward over time. This type of learning is crucial in decision-making as it allows agents to adapt to changing environments and learn from their experiences.
Importance of Reinforcement Learning in Decision-Making
RL is essential in various fields, including robotics, gaming, and autonomous vehicles, where it enables agents to learn sophisticated strategies and make decisions based on sensory inputs. RL’s ability to learn from trial and error makes it a powerful tool for solving complex problems.
Key Components of Reinforcement Learning
- Agent: The decision-maker or learner that interacts with the environment.
- Environment: The system outside of the agent that it communicates with.
- State: The current situation or condition of the environment.
- Action: The decision made by the agent in response to the state.
- Reward: The feedback received by the agent for its actions, which helps it learn to make better decisions.
The key components of RL include the agent, environment, state, action, and reward. The agent is the decision-maker that interacts with the environment. The environment is the system outside of the agent that it communicates with. The state is the current situation or condition of the environment. The action is the decision made by the agent in response to the state. The reward is the feedback received by the agent for its actions, which helps it learn to make better decisions.
Markov Decision Processes (MDPs) and Their Components
- MDPs: A mathematical framework for modeling decision-making problems in RL. MDPs consist of a set of states, actions, and transitions between states, along with a reward function.
- Components of MDPs:
- States: The set of possible states in the environment.
- Actions: The set of possible actions the agent can take.
- Transition Model: The probability of transitioning from one state to another based on the action taken.
- Reward Function: The reward received by the agent for taking an action in a particular state.
Exploration vs. Exploitation
In reinforcement learning, there is a crucial trade-off between exploring new actions and exploiting known ones. Exploration involves trying new actions to gather more information about the environment, while exploitation involves using known actions to maximise the cumulative reward. If an agent only exploits known actions, it may miss out on better opportunities. On the other hand, if it only explores, it may never find a good policy.To balance this trade-off, strategies like epsilon-greedy and softmax policies are used. Epsilon-greedy involves choosing a random action with a probability of epsilon and the best action with a probability of 1−𝜖1−ϵ. Softmax policies involve choosing actions based on their probabilities, which are calculated using the softmax function.For example, in a game where a mouse can collect cheese, exploration allows the mouse to discover new sources of cheese, while exploitation helps it maximise the reward by focusing on the best known sources. By balancing exploration and exploitation, the mouse can find the optimal policy to maximise its rewards.In real-life applications, such as autonomous vehicles and retail marketing, balancing exploration and exploitation is crucial to achieve the best results.
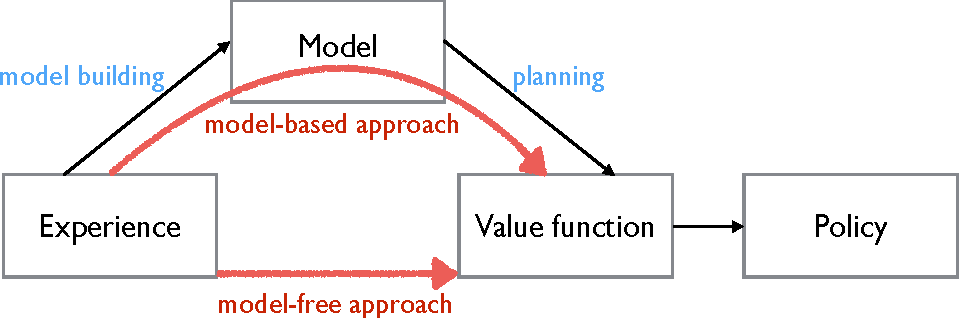
Model-Free Reinforcement Learning
Model-Free Reinforcement LearningModel-free reinforcement learning is a type of reinforcement learning where the agent learns to make decisions without having a model of the environment. This means the agent doesn’t know how the environment will react to its actions, so it must learn through trial and error.
Q-Learning Algorithm
The Q-learning algorithm is a popular model-free reinforcement learning method. It learns the action- value function Q(s, a), which tells the agent how good it is to take a particular action in a particular state. The Q-learning algorithm updates the action-value function based on the difference between the expected and observed rewards. This helps the agent learn which actions are good and which are bad.
SARSA Algorithm
The SARSA algorithm is another model-free reinforcement learning method. It learns the state-action value function Q(s, a, s’), which tells the agent how good it is to take a particular action in a particular state and end up in another state. The SARSA algorithm updates the state-action value function based on the difference between the expected and observed rewards. This helps the agent learn which actions are good and which are bad in different situations.
Temporal Difference (TD) Learning
Temporal difference learning is a model-free reinforcement learning method that learns the value function V(s), which tells the agent how good it is to be in a particular state. The TD learning algorithm updates the value function based on the difference between the expected and observed rewards. This helps the agent learn which states are good and which are bad.
Model-Based Reinforcement Learning
In model-based reinforcement learning, the agent learns a model of the environment and uses it to plan and update its policy. This is different from model-free RL, where the agent learns directly from interactions with the environment without building an explicit model.One popular model-based RL algorithm is value iteration. In value iteration, the agent learns the value function V(s), which represents the expected cumulative reward from starting in state s and following the optimal policy. The agent updates V(s) by iteratively applying the Bellman equation, which relates the value of a state to the values of its successor states.Another model-based RL algorithm is policy iteration. In policy iteration, the agent learns both the value function V(s) and the policy π(s), which specifies the action to take in each state. The agent alternates between evaluating the current policy by computing V(s) and improving the policy by greedily selecting actions that maximise the expected reward.The Dyna-Q algorithm combines model-based and model-free RL. Dyna-Q learns a model of the environment and uses it to generate simulated experiences, which are then used to update the Q-function as in Q- learning.
This allows Dyna-Q to learn more efficiently than pure model-free RL by leveraging the learned model.Model-based RL can be more sample-efficient than model-free RL, as the agent can learn from simulated experiences generated from the model. However, learning an accurate model can be challenging, especially in complex environments. The choice between model-based and model-free RL often depends on the specific problem and the available computational resources.
Deep Reinforcement Learning
Deep Q-Networks (DQN)
Deep Q-Networks (DQN) are a type of deep reinforcement learning algorithm that uses a neural network to learn the action-value function Q(s, a). This function represents the expected return when taking action a in state s. DQN uses a deep neural network to approximate the Q-function and updates it based on the difference between the expected and observed rewards. This allows the agent to learn complex policies by exploring the environment and receiving rewards or penalties for its actions.
Policy Gradient Methods
Policy gradient methods are another type of deep reinforcement learning algorithm that learns the policy π(s) directly. This policy represents the probability distribution over actions given the state s. Policy gradient methods use the policy gradient theorem to update the policy based on the expected rewards. This allows the agent to learn complex policies by optimizing the expected cumulative reward.
Actor-Critic Methods
Actor-critic methods combine the strengths of policy gradient methods and value-based methods. They learn both the policy π(s) and the value function V(s) using a neural network. The policy π(s) represents the probability distribution over actions given the state s, while the value function V(s) represents the expected return when taking the optimal action in state s. Actor-critic methods use the policy gradient theorem to update the policy and the value function based on the expected rewards. This allows the agent to learn complex policies by optimizing the expected cumulative reward.
Multi-Armed Bandits
Multi-armed bandits are a type of problem where an agent must choose between multiple actions to maximize the cumulative reward. This is similar to choosing which slot machine to play in a casino. The key challenge is balancing exploration and exploitation to find the best action. Strategies for multi- armed bandits include epsilon-greedy and softmax policies.
Monte Carlo Methods
Monte Carlo methods are a class of algorithms that use random sampling to estimate the expected rewards. These methods are useful when the environment is complex and the reward function is difficult to model. Monte Carlo rollouts and Monte Carlo tree search are two popular strategies for Monte Carlo methods.
Function Approximation Techniques
Function approximation techniques are used to approximate the value function V(s) or the policy π(s) using a learned model. This is useful when the state space is large and the value function or policy is difficult to represent exactly. Common function approximation techniques include neural networks, decision trees, and linear regression.These advanced topics in RL provide more sophisticated tools for solving complex decision-making problems. By understanding these techniques, you can develop more effective RL algorithms and apply them to a wider range of applications.
Applications of Reinforcement Learning
Robotics
RL is used in robotics to enable robots to learn complex tasks such as grasping and manipulation. By interacting with their environment and receiving rewards or penalties, robots can learn to perform tasks like assembly, welding, and even surgery. This technology has the potential to revolutionize manufacturing and healthcare.
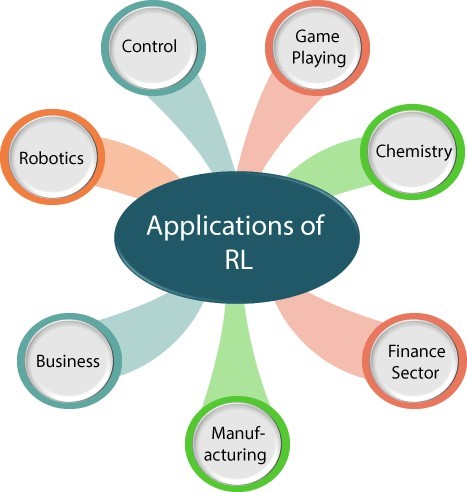
Game Playing (e.g., AlphaGo)
RL has been used to create AI systems that can play complex games like Go, chess, and poker. AlphaGo, for instance, used RL to learn how to play Go by analyzing millions of games and adapting its strategy accordingly. This technology has significant implications for the development of AI systems that can play complex games and even interact with humans.
Autonomous Vehicles
RL is used in autonomous vehicles to enable them to learn how to navigate and make decisions in real- time. By interacting with their environment and receiving rewards or penalties, autonomous vehicles can learn to avoid obstacles, follow traffic rules, and even anticipate the actions of other vehicles. This technology has the potential to transform the way we travel and interact with our environment.
Challenges and Future Directions
Sample Efficiency
One of the biggest challenges in reinforcement learning is sample efficiency. This refers to the ability of an RL algorithm to learn from a limited number of samples. In many real-world applications, it is not feasible to gather a large amount of data, so RL algorithms need to be able to learn effectively from the data they do have. This is particularly important in applications where the environment is changing rapidly or where the agent needs to adapt quickly to new situations.
Generalisation to New Environments
Another challenge in RL is generalisation to new environments. RL algorithms are typically trained on a specific environment or set of environments, but they often struggle to generalise to new environments that are similar but not identical. This is a significant challenge because it means that RL algorithms may not be able to adapt to changing environments or new situations.
Ethical Considerations
Finally, there are ethical considerations that need to be taken into account when using RL in decision- making. For example, RL algorithms may not always make decisions that are fair or transparent, which can have significant implications for individuals and society as a whole. Additionally, RL algorithms may be used in applications where the consequences of their decisions are severe, such as in autonomous vehicles or healthcare.
Conclusion
In this comprehensive guide to deep reinforcement learning, we have covered the key concepts and algorithms that are essential for understanding this powerful tool for decision-making. We have seen how reinforcement learning allows agents to adapt to changing environments and learn from their experiences, making it crucial in modern AI.
Recap of Key Concepts and Algorithms
We have covered the key components of reinforcement learning, including the agent, environment, state, action, and reward. We have also explored the different types of reinforcement learning algorithms, including model-free and model-based methods, as well as deep reinforcement learning algorithms that combine deep learning with RL.
Importance of Reinforcement Learning in Modern AI
Reinforcement learning is a fundamental component of modern AI, enabling agents to learn complex behaviours and make decisions in dynamic environments. Its applications are vast, ranging from robotics and game playing to autonomous vehicles and healthcare. As AI continues to advance, reinforcement learning will play a critical role in shaping the future of decision-making and problem- solving.

